Have you ever wondered which database Facebook (FB) uses to store the profiles of its 2.3B+ users? Is it SQL or NoSQL? How has FB database architecture evolved over the past 15+ years? As an engineer on FB’s database infrastructure team from 2007 to 2013, I had a front-row seat to witness this evolution. There are invaluable lessons to be learned by better understanding the evolution of the database into the world’s largest social network, even though most of us won’t face exactly the same challenges in the near future. That’s because the fundamental principles underpinning FB’s globally distributed Internet-scale architecture today apply to many business-critical enterprise applications, such as multi-user SaaS, retail product catalog/payment, travel bookings, and game leaderboards.
As
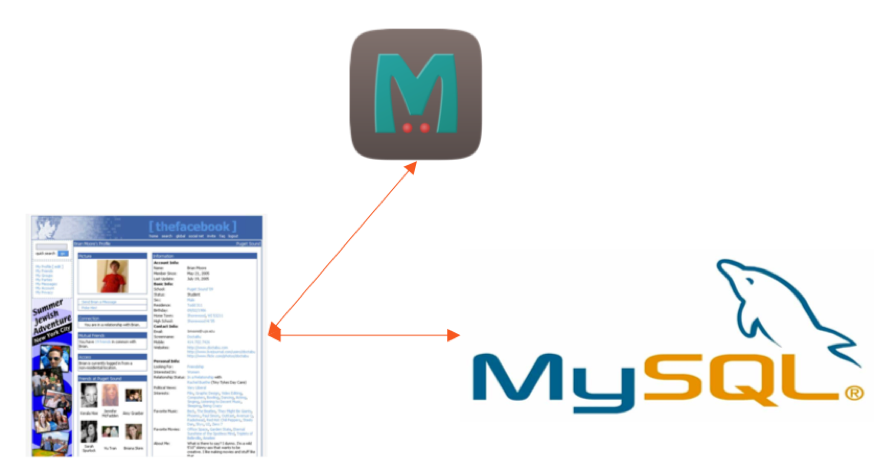
any FB user can easily understand, your profile is not simply a list of attributes like name, email, interests, etc. In fact, it is a rich social graph that stores all friends/family relationships, groups, registrations, likes, shares, and more. Given the data modeling flexibility of SQL and the ubiquity of MySQL when FB started, this social graph was initially built as a PHP application powered by MySQL as a persistent database and memcache as a “lookaside” cache.
Original Facebook
database architecture
In the looklooklookside caching pattern, the app first requests data from the cache instead of the database. If the data is not cached, the application obtains the data from the backup database and caches it for later readings. Note that the PHP application accessed MySQL and memcache directly without any intermediate layer of data abstraction.
The
meteoric success of Growing Pains FB starting in 2005 put enormous pressure on the simplistic database architecture highlighted in the previous section. The following were some of the growing pains that FB engineers had to solve in a short period of time.
Engineers
had to work with two data
warehouses with two very different data models: a large collection of MySQL master-slave pairs to persistently store data in relational tables, and an equally large collection of memcache servers to store and serve flat key-value pairs derived (some indirectly) from SQL query results. Working with the database tier now required first gaining intricate knowledge of how the two stores worked together. The net result was the developer’s loss of agility.
MySQL’s inability to scale write requests beyond a node became a killer problem as data volumes grew by leaps and bounds. MySQL’s monolithic architecture essentially forced application-level fragmentation from the start. This meant that the application now tracked which MySQL instance is responsible for storing which user’s profile. Development and operational complexity grow exponentially when the number of such instances grows from 1 to 100 and then explodes by 1000. Note that adherence to such an architecture meant that the application no longer uses the database to perform cross-fragment transactions and joins, thus giving up the full power of SQL (as a flexible query language) to scale horizontally.
Multi-Datacenter
, geo-redundant replication Managing data
center failures also became a critical concern, which meant storing MySQL slaves (and corresponding memcache instances) in multiple geo-redundant data centers. Refining and implementing failovers was no easy task in itself, but given master-slave asynchronous replication, newly confirmed data would still be missing every time such a failover was performed.
Loss of consistency between cache and database
The memcache versus a remote region MySQL slave cannot immediately serve strong consistent reads (also known as read after write) due to asynchronous replication between master and slave. And, the resulting outdated readings in the remote region can easily lead to confused users. For example, a friend request may appear as accepted for one friend while being presented as pending for the other.
Enter TAO, a NoSQL graph API in
fragmented SQL
In early 2009, FB began building TAO, a FB-specific NoSQL graph API built to run on fragmented MySQL. The goal was to resolve the issues highlighted in the previous section. TAO stands for “The Associations and Objects”. Even though the CAT design was first published as a paper in 2013, the CAT implementation was never open source given the proprietary nature of the FB social graph.
CAT represented data elements as nodes (objects) and the relationships between them as edges (associations). FB app developers loved the API because they could now easily manage database updates and queries needed for their application logic without direct knowledge of MySQL or even memcache.
Architecture
As shown in the figure below, TAO essentially converted FB’s 1000 manually fragmented MySQL master-slave pairs into a highly scalable, self-fragmenting, geo-distributed database cluster. All objects and associations on the same partition are persistently stored in the same MySQL instance and cached in the same farm in each caching cluster. The placement of individual objects and associations can be directed to specific fragments at the time of creation when necessary. Controlling the degree of data placement proved to be an important optimization technique for providing low-latency data access.
SQL-based access patterns, such as cross-fragment ACID transactions and joins, were not allowed in CAT as a means of preserving such low-latency guarantees. However, it supported non-atomic writes of two partitions in the context of an association update (whose two objects can be on two different partitions). In case of errors after a partition upgrade, but before the second partition upgrade, an asynchronous repair job would clean up the “crash” association at a later time.
Partitions can be migrated or cloned to different servers in the same cluster to balance load and smooth out load spikes. Load spikes were common and occur when a handful of objects or associations become extremely popular as they appear in the news feed of tens of millions of users at the same time.
TAO Architecture (Source: FB Engineering Blog)
Is there a general-purpose enterprise solution?
FB had no choice but to massively scale the MySQL database layer responsible for its user’s social graph. Neither MySQL nor the other SQL databases available at the time could solve this problem on their own. Therefore, FB used its significant engineering power to essentially create a custom database query layer that abstracted the underlying fragmented MySQL databases. In doing so, it forced its developers to completely forgo SQL as a flexible query API and adopt TAO’s custom NoSQL API.
Most of us in the enterprise world don’t have problems at Facebook scale, but nevertheless we want to scale out SQL databases on demand. We love SQL for its flexibility and ubiquity, which means we want to scale without giving up SQL. Is there a general-purpose solution for companies like us? The answer is yes!
Hello Distributed SQL!
Monolithic SQL databases have been trying for 10+ years to be distributed to solve the scale-out problem. As “Rise of Globally Distributed SQL Databases” highlights, the first wave of such databases was called NewSQL and included databases such as Clustrix, NuoDB, Citus, and Vitess. These have had limited success in moving fragmented SQL databases manually. The reason is that the new value created is not enough to radically simplify the developer experience and operations. Clustrix and NuoDB demand a specialized, highly reliable, low-latency data center infrastructure – modern cloud-native infrastructure looks exactly the opposite. Citus and Vitess simplify the operations experience to some extent by automatically fragmenting the database, but then hurt the developer by not giving them a single logical distributed SQL database.
We are now in the second generation of distributed SQL databases where massive scalability and global distribution of data are built into the database layer unlike 10 years ago when Facebook had to incorporate these features into the application layer.
Inspired by
Google Spanner
While FB was building TAO, Google was building Spanner, a completely new and globally consistent database to solve very similar challenges. Spanner’s data model was less of a social graph, but more of a traditional random-access OLTP workload that manages Google users, client organizations, AdWords credits, GMail preferences, and more. Spanner was first introduced to the world in the form of designer paper in 2012. It started in 2007 as a transactional key-value store, but later evolved into a SQL database. The shift to SQL as the sole client language accelerated when Google engineers realized that SQL has all the right constructs for agile application development, especially in the cloud-native era, where infrastructure is far more dynamic and prone to failures than the highly reliable private data centers of the past. Today, several modern databases (including YugabyteDB) have brought the design of Google Spanner to life entirely in open source.
Handling the volume of data at Internet scale with Sharding
ease is fully automatic in the Spanner architecture. In addition, partitions are automatically balanced across all available nodes as new nodes are added or existing nodes are deleted. Microservices that need massive write scalability can now rely directly on the database instead of adding new layers of infrastructure similar to what we saw in the FB architecture. There is no need for an in-memory cache (which offloads read requests from the database, thus freeing it up to serve write requests) and there is also no need for a TAO-like application layer that performs fragment management.
Extreme resilience against failures
A key difference between Spanner and the
legacy NewSQL databases we reviewed in the previous section is Spanner’s use of partition-distributed consensus to ensure that each partition (and not simply each instance) remains highly available in the presence of failures. As in TAO, infrastructure failures always affect only a subset of data (only those fragments whose leaders are partitioned) and never the entire cluster. And, given the ability of the remaining fragment replicas to automatically choose a new leader in seconds, the group exhibits self-healing characteristics when subjected to failure. The application remains transparent to these cluster configuration changes and continues to operate normally without interruption or slowdown.
The
benefit of a globally consistent database architecture is that microservices that need absolutely correct data in multi-zone and multi-region write scenarios can finally rely directly on the database. The conflicts and data loss observed in typical multimaster deployments of the past do not occur. Features such as table-level and row-level geographic partitioning ensure that data relevant to the local region remains leading in the same region. This ensures that the highly consistent read path never incurs latency between regions/WANs.
Total power of SQL and
distributed
ACID transactions
Unlike legacy NewSQL databases, SQL and ACID transactions in their full form can be supported on the Spanner architecture. Single-key operations are, by default, strongly consistent and transactional (the technical term is linear). Single-partition transactions, by definition, target a single partition and can therefore be committed without the use of a distributed transaction manager. Multi-fragment (also known as distributed) ACID transactions involve a 2-phase commit using a distributed transaction manager that also tracks clock biases across nodes. Joins of multiple partitions are handled similarly by querying data on the nodes. The key here is that all data access operations are transparent to the developer who simply uses regular SQL constructs to interact with the database.
Summary
The stories of scaling data infrastructure at any of the tech giants, including FB and Google, make for a great engineering apprenticeship. At FB, we took the path of building TAO, which allowed us to preserve our existing investment in fragmented MySQL. Our application engineers lost the ability to use SQL, but they got a bunch of other benefits. Google engineers faced similar challenges, but chose a different path when creating Spanner, an entirely new SQL database that can scale horizontally, replicate geographically seamlessly, and easily tolerate infrastructure failures. FB and Google are incredible success stories, so we can’t say one path was better than the other. However, when we broaden the horizon to general-purpose enterprise architectures, Spanner is ahead of TAO because of all the reasons highlighted in this post. By building the YugabyteDB storage layer on the Spanner architecture, we believe we can bring developer agility from tech giants to today’s enterprises.
Updated March 2019.
What’s next?
Compare YugabyteDB
- in depth with databases like CockroachDB, Google Cloud Spanner, and MongoDB. Get started with YugabyteDB
- macOS, Linux, Docker, and Kubernetes
- Contact us for more information on licensing, pricing, or to schedule a technical overview.
on
.