What are graph databases?
A chart database stores information such as relationships between entities and represents this data using nodes and edges, rather than using rows and columns in tables. For example, a database of customers, orders, and products:
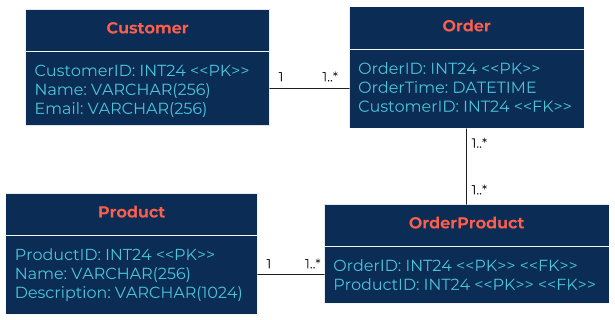
Figure 1. Customer and order data as relational database tables. 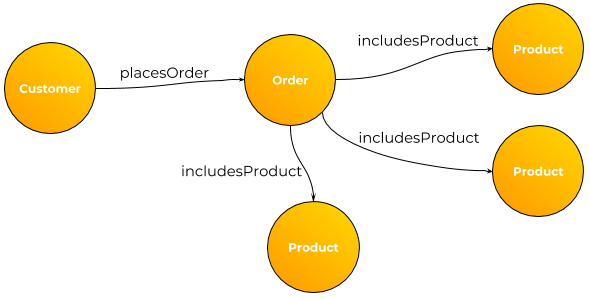 Figure 2. Customer and order data as a graph.
Figure 2. Customer and order data as a graph.
Figure 1 illustrates a typical relational database with four linked tables representing the relationship between ordering customers, which are made up of products.
In Figure 2, the data is modeled in a graph, with nodes for the main object types and borders for the relationships between them.
Representing data as a graph
allows for numerous benefits over relational databases
: Increased data complexity: In a graph database,
complex interdependent relationships between nodes can be added and removed in an easy-to-understand way, whereas within a tabular database this becomes exponentially difficult as data sources are introduced. additional and use cases. Similarly, in a “NoSQL” document database, it is complex to optimize the joining operations between documents.
Constant evolution of the data model: In a chart, the data model can be continuously modified without having to make costly schema changes, as you would with table-based data. For example, in a scenario where a new property is required for a given relationship, this property can simply be added to the nodes.
Simpler relationship-based queries
: A database of summary charts bridges complexity and provides a query language that makes it easier to formulate relationship-based data questions. Whereas, performing complex queries on linked tables can be difficult to understand and difficult to optimize.
Therefore, graph databases are very beneficial for specific use cases:
- Fraud detection 360 Customer views
- Recommendation engines
- mapping AI Knowledge
- Graphs
- Social Media
- Mapping
Network/operations
Supply Chain
Graph
database
Use cases
Fraud detection
Business events and customer data, such as new accounts, loan applications, and credit card transactions, They can be modeled on a graph to detect fraud. By looking for suspicious patterns of customer activity metadata and cross-references with previously identified frauds, we can point to potential frauds that may be ongoing.
Specifically, we extract entities from a large database of business activities, make relationships between them, and model them in a graph. We can then use a technique called “Entity Link Analysis” to identify suspicious links between entity types that may indicate fraudulent behavior.
Typically, in a fraud detection graph, we’ll use entities of people such as names and dates of birth, as well as contextual entities such as IP addresses, device identifiers, and access times. We can then analyze the links between these entities and flag those that have previously been flagged as fraudulent. When entities that are marked as fraudulent begin to cross paths with those that are not marked as fraudulent, suspicion begins to arise. For example, the use of multiple bank accounts on a single device that has previously been used to access fraudulent accounts.
Suspicious links can be flagged for investigation by humans, and also marked as “high risk” so that future results can be double-checked.
In addition to manually verifying results, automation can be used and continuously improved through the analysis of identified fraud patterns. By collecting the before-and-after graphical patterns of the analyzed suspected fraud cases, we can generate inputs for a machine learning (ML) training suite. As more data flows into the graph, we input it into the ML model to mark whether the patterns in the graph could represent potential fraud and whether they are blocked or flagged for human investigation.
A compelling
use of graph databases is to integrate a company’s data from its entire estate of data silos. This generates a considered view of the big picture and can be used to enhance information, for example by enabling a “360-degree customer view”.
It is typical for a company to have data about customers scattered across its wealth and locked into platforms used by particular verticals of the company. Sales in SalesForce, marketing in HubSpot, email tracking in MailChimp, website tracking in Mixpanel, etc. To create a 360-degree customer view, we stream data from these services to a graph, using a common data model to provide integration.
Previously, the
sheer scale of integrating so much data into a single graph would have been difficult to provision and scale, however, the advent of horizontally scalable graph databases like DataStax Enterprise Graph and data streaming frameworks like Apache Kafka has provided a scalable reference architecture that can scale to even the largest enterprise.
Having a live chart of all known aspects about the customer allows for up-to-date rich queries about customers and trends. Uses include deep dives into particular demographics or customer sectors, behavioral aggregations based on marketing events, etc.
Initially,
data can be made available to marketers through rich visual query interfaces, with live views of customer clicks, interactions, and purchases, for example, during a promotional event. As more features are developed from customer data, machine learning models can be trained to predict the impact of planned marketing activity on customer engagement with the business.
Network
mapping
Infrastructure mapping and inventory are a natural fit for representation as a graph. In particular, when mapping the relationships between connected physical/virtual hardware and the services they support. A company will use CMDB (configuration management databases) and/or service catalogs to maintain inventory of its systems. They are used to keep track of components, their purpose, software versions, and the interdependencies between them.
A graph of
the relationships between infrastructure components not only allows interactive visualizations of network status, but also network tracing algorithms to traverse the graph. For example, algorithms
for:
Dependency management: identify single points of failure and simulate the impact of your failure on services, to identify cascading failures before they occur
. Identification of bottlenecks:
Find weak links in network routing that could cause bottlenecks at times of high network utilization
.
Latency assessment: Estimate the latency between network paths and the impact on services accessed from multiple geographic regions.
As an infrastructure grows, it can be difficult to assess the full impact across the entire network. With a graphical database, you can run metrics to estimate impact before installing updates, as well as to debug infrastructure issues on an active network. Intelligent algorithms can identify bottlenecks and recommend routing changes or update paths.
At 6point6 we have extensive experience in delivering graph database solutions for our clients and their maintenance using our DataOps methodology.
For more information, please contact us.
Written by Dr. Daniel Alexander Smith, Principal Architect of Big Data