What does WGET do?
Once installed, the WGET command allows you to download files over the TCP/IP protocols: FTP, HTTP, and HTTPS.
If you’re a
Linux or Mac user, WGET is already included in the package you’re running or it’s a trivial case of installing from whichever repository you prefer with a single command.
Unfortunately, it’s not that simple on Windows (although it’s still very easy!).
To run WGET you need to download, unzip and install manually.
Install WGET
on Windows 10
Download classic 32-bit version 1.14 here or go to this collection of Windows binaries in Eternally Bored here for later versions and faster 64-bit builds
.
Here is the downloadable zip file for 64-bit version 1.2.
If you want to be able to run WGET from any directory within the command terminal, you’ll need to get information about path variables in Windows to figure out where to copy your new executable. By following these steps, you can convert WGET to a command that you can run from any Command Prompt directory.
Run WGET from anywhere
First, we need to determine where to copy WGET.exe.
After downloading wget.exe
(or unzipping the associated distribution zip files) open a command terminal by typing
“cmd” in the search menu:
Let’s move wget.exe to a Windows directory that will allow WGET to run from anywhere
.
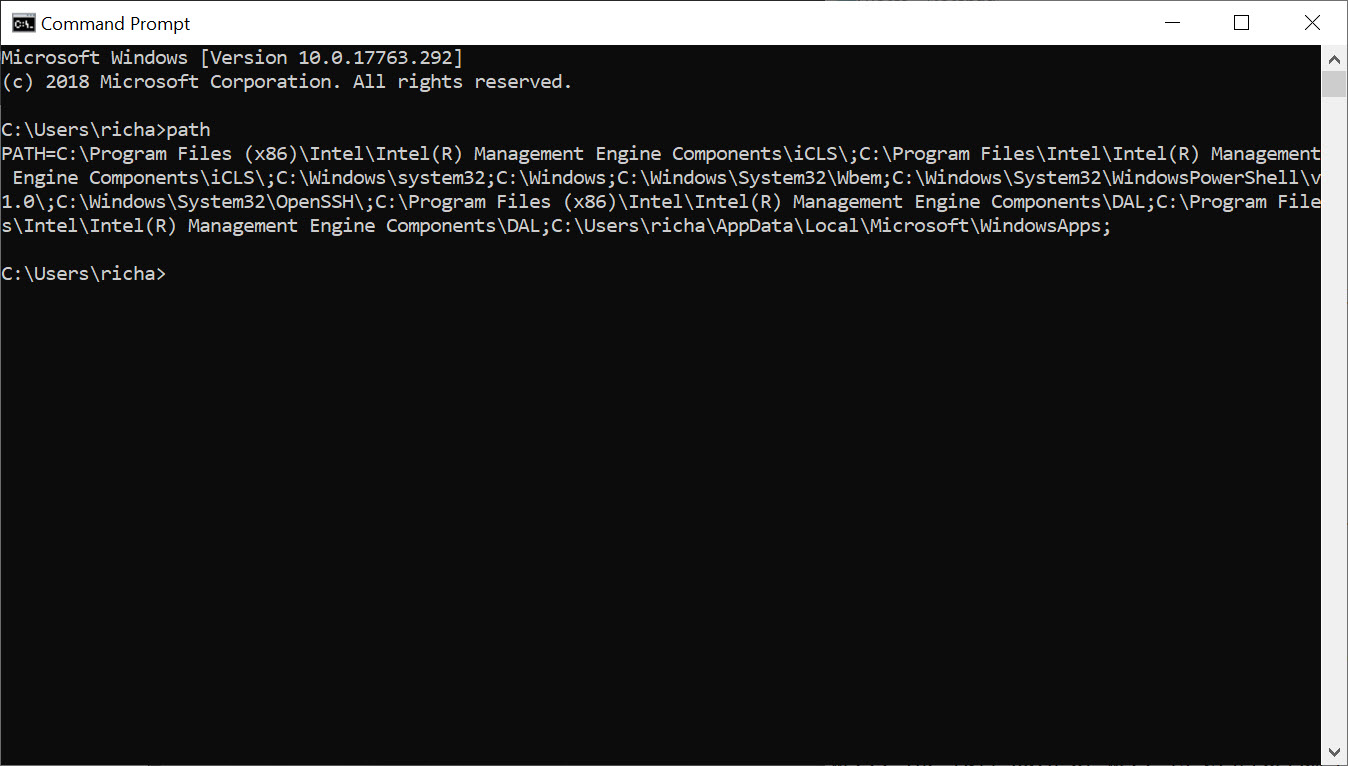
First, we need to figure out what directory it should be. Type
:path
You should see something like this
:<img src="https://builtvisible.com/wp-content/uploads/2009/02/1-type-cmd.jpg" alt="Typing
path
in cmd in Windows 10″ />Thanks to the
environment variable “Path”, we know that we need to copy wget.exe to the folder location c:\Windows\System32
.
Go ahead and copy WGET.exe to the System32 directory and restart your command prompt. Restart the command terminal and test WGET
Yes
you want to test that WGET works correctly, restart your terminal and type
:
wget -h
If you have copied the file to the right place, you will see a help file appear with all available commands
.
So, you should see something like this:
Now it’s time to start.
Get started with
WGET
Seeing that we will be working in the command prompt, let’s create a download directory only for WGET downloads.
To create a directory, we will use the md (“make directory”) command.
Switch to c:/ prompt y type:
md wgetdown
Then, change to your new directory
and type “dir” to see the contents (blank).
Now, you’re ready to do some downloads.
Sample commands
Once you have installed WGET
and you’ve created a new directory, all you have to do is learn some of the finer points of WGET arguments to make sure you get what you need.
The Gnu.org WGET manual is a particularly useful resource for those inclined to really learn the details.
However, if you want some quick commands, read on. I’ve listed a set of instructions for WGET to recursively mirror your site, download all images, CSS, and JavaScript, locate all URLs (to make the site work on your local machine), and save all pages as a .html file.
To mirror
your site, run this command
:wget -r https://www.yoursite.com To mirror the site and
locate all urls
:wget -convert-links -r https://www.yoursite.com
To create a full offline mirror of a
site:wget -mirror –
convert-links -adjust-extension -page-requisites
–
no-parent https://www.yoursite.com
To mirror the site and save files as .html:
wget -html-extension
-r https://www.yoursite.com
To download all jpg images from a site
:
wget -A “*.jpg” -r https://www.yoursite.com
For more file type-specific operations, check out this helpful thread on Stack.
Set a
different user agent:
Some web servers are configured to deny the default WGET user agent, for obvious bandwidth-saving reasons. You can try changing your user agent to avoid this. For example, posing
as Googlebot:
wget -user-agent=”Googlebot/2.1 (+https://www.googlebot.com/bot.html)” -r https://www.yoursite.com
“spider” mode of Wget
:Wget
can
retrieve pages without saving them, which can be a useful feature in case you’re looking for broken links on a website. Remember to enable recursive mode, which allows wget to scan the document and look for links to traverse.
wget
-spider -r https://www.yoursite.com
You can also save this to a log file by adding this option:
wget -spider –
r https://www.yoursite.com -o wget.log
Enjoy using this powerful tool, and I hope you enjoyed my tutorial. Comments welcome!